SparkSQL执行时参数优化
spark.sql.shuffle.partitions 和 spark.default.parallelism 的区别
在实际测试中:
- spark.default.parallelism 只有在处理RDD时才会起作用,对spark SQL无效。
- spark.sql.shuffle.partitions则是对spark SQL专有的设置
因此,在提交作业时:
spark-submit --conf spark.sql.shuffle.partitions=20 --conf spark.default.parallelism=20
c3p0、dbcp、druid三大连接池的区别详解
|连接池|介绍| |:—|:—:| |c3p0|开放的源代码的JDBC连接池| |DBCP|依赖Jakarta commons-pool对象池机制的数据库连接池 | |druid|阿里出品,淘宝与支付宝专用的数据库连接池,它还包括了一个ProxyDriver、一系列内置的JDBC组件库,一个SQL Parser。支持所有JDBC兼容的数据库|
数据库连接池的作用以及配置
连接池是创建和管理多个连接的一种技术,这些连接可被需要使用它们的任何线程使用。
主要优点有:
(1) 缩短了连接创建时间
(2) 简化的编程模型
(3) 受控的资源使用
即节约资源,用户访问高效;这里能否节约资源,使用数据连接池的方法对数据解析处理。
spark jdbc 参数解读与优化
sparksql 还包括一个可以使用JDBC从其他数据库读取数据的数据源。与使用jdbcRDD相比,应优先使用此功能。这是因为结果作为 dataframe返回,它们可以在sparksql中轻松处理或与其他数据源连接。
(???) 很多人在spark中使用默认提供的jdbc方法时,在数据库数据较大时经常发现任务 hang 住,其实是单线程任务过重导致,这时候需要提高读取的并发度。
Spark On Yarn中Yarn分配资源的时候vcore怎么理解
spark sql优化
数据倾斜
数据倾斜的后果:程序执行缓慢、报错OOM。
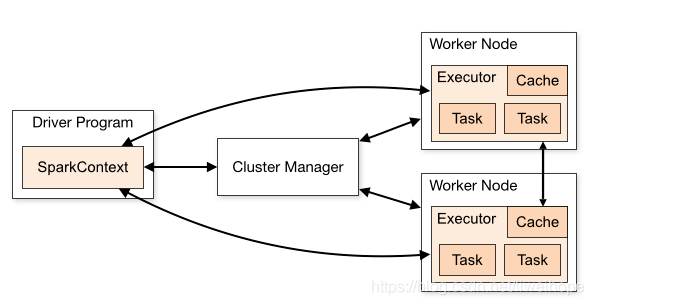
Spark的driver理解和executor理解
spark 共享变量 – 累加器
累加器概念图:
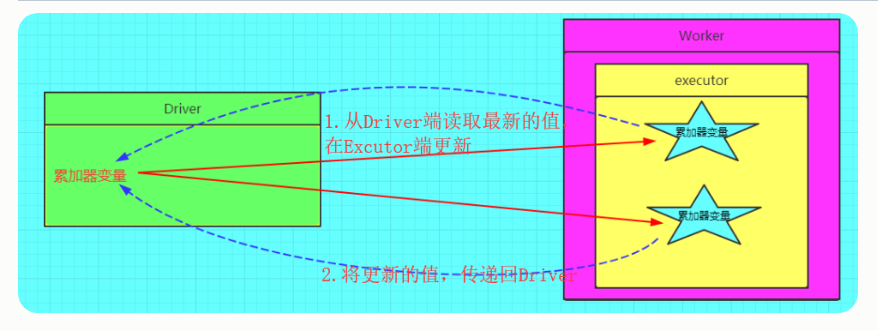
累加器
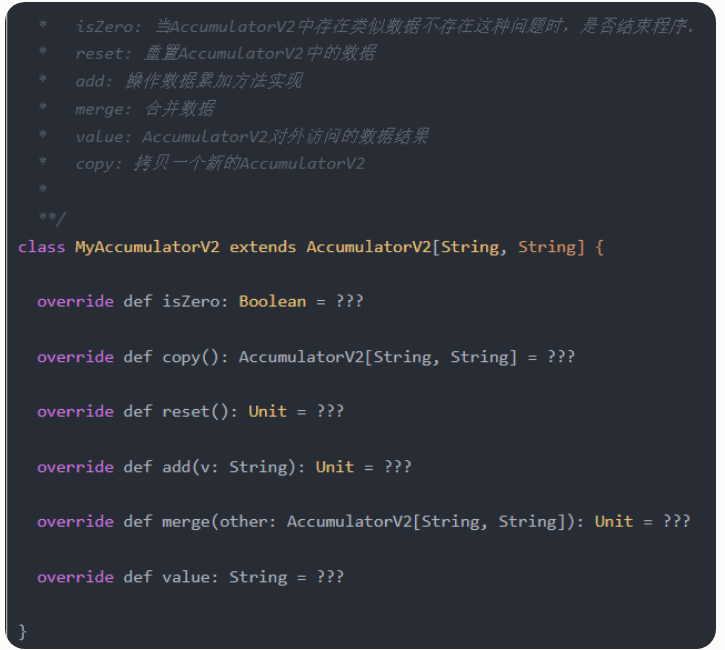
自定义累加器(通过AccumulatorV2),必须重写的有:
reset:用于重置累加器为0
add:用于向累加器加一个值
merge:用于合并另一个同类型的累加器到当前累加器
其他必须重写的方法有:
copy():创建此累加器的新副本
isZero():返回该累加器是否为零值
value():获取此累加器的当前值
spark 内存空间管理
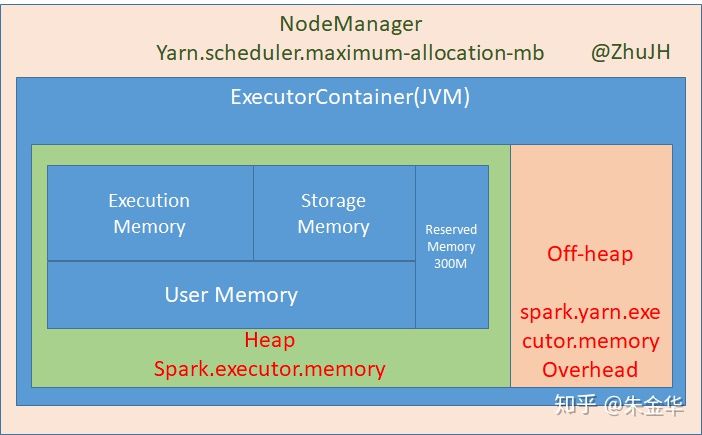
分为堆内内存和堆外内存。
堆内内存分为:reserved memory(300M)、(用户管理)user memory、(spark管理)storage memory、execution memory。spark管理的内存通过spark.memory.fraction控制,默认为0.6.
一些参考资料
- 用 Spark 处理复杂数据类型(Struct、Array、Map、JSON字符串等)
- Spark SQL读数据库时不支持某些数据类型的问题
- How to get keys and values from MapType column in SparkSQL DataFrame
- Spark 指南:Spark SQL(三)—— 结构化类型
- SparkSQL读取MySQL数据tinyint字段转换成boolean类型的解决方案/sqoop中也有该问题
- Schema for type Any is not supported
- 数据类型
- Spark中Map与MapPartition和的详细区别
- Spark Dataset DataFrame空值null,NaN判断和处理
- Spark性能优化指南——基础篇
- Spark性能优化指南——高级篇
- 一篇文章搞清spark内存管理
- Spark性能调优方法
sparksql 解析数据时相关java知识
System.getProperty()
获取指定键指示的系统属性。
user.dir 用户的当前工作目录
os.name 操作系统的名称
user.name 用户的账户名称
user.home 用户的主目录
System.getProperty(“user.dir”)的理解 – 工程根目录
Java的Class.getClassLoader().getResourceAsStream()与Class.getResourceAsStream()理解