背景
数据湖是一个集中式存储库,可存储任意规模结构化和非结构化数据,支持大数据和AI计算。数据湖构建服务(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
| 数据孤岛分为物理性和逻辑性两种。物理性的数据孤岛指的是,数据在不同部门相互独立存储,独立维护,彼此间相互孤立,形成了物理上的孤岛。逻辑性的数据孤岛指的是,不同部门站在自己的角度对数据进行理解和定义,使得一些相同的数据被赋予了不同的含义,无形中加大了跨部门数据合作的沟通成本。 |
数据湖解决方案中关键的一个环节就是数据存储和计算引擎之间的适配。为解决该问题Netflix开发了Iceberg,目前已经是Apache的顶级项目。
Iceberg
数据湖技术代表之一Apache Iceberg。
| Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table. |
定位是在计算引擎之下,又在存储之上。同时,它也是一种数据存储格式,Iceberg则称其为”table format”。
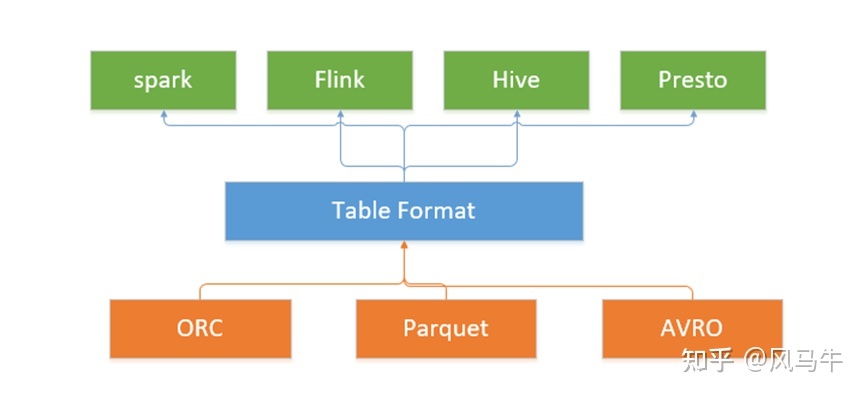
特性
- 数据存储、计算引擎插件化
- 实时流批一体
- 数据演化(table evolution)
Iceberg 可以通过SQL的方式进行表级别模型演进。进行这些操作的时候,代价极低,不存在读出数据重写写入或者迁移数据这种费事费力的操作。 - 模式演化(schema evolution)
ADD/Drop/Rename/Update/Reorder
iceberg 保证模式演化是没有副作用的独立操作流程,一个元数据操作,不会涉及到重写数据文件的过程。 - 分区演化(partition evolution)
iceberg可以在一个已存在的表上直接修改,因此iceberg的查询流程并不和分区信息直接关联。 - 列顺序演化(sort order evolution)
- 隐藏分区(hidden partition)
Iceberg的分区信息并不需要人工维护, 它可以被隐藏起来. - 镜像数据查询(time travel)
Iceberg提供了查询表历史某一时间点数据镜像(snapshot)的能力. 通过该特性技术人员可以将最新的SQL逻辑, 应用到历史数据上. - 支持事务(ACID)
- 基于乐观锁的并发支持
Iceberg基于乐观锁提供了多个程序并发写入的能力并且保证数据线性一致. - 文件级数据剪裁