flink:容错机制
一致性检查点(checkpoints)
flink 故障恢复机制的核心,就是应用状态的一致性检查点。
有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
可以理解为:checkpoint是将state数据定时持久化存储了。
检查点实现算法
flink的checkpoint底层使用了 chandy-Lamport algorithm分布式快照算法可以保证数据在分布式环境下的一致性。
检查点分界线:
- flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来将一条流上数据按照不同的检查点分开;
- 分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中。
checkpoint执行流程
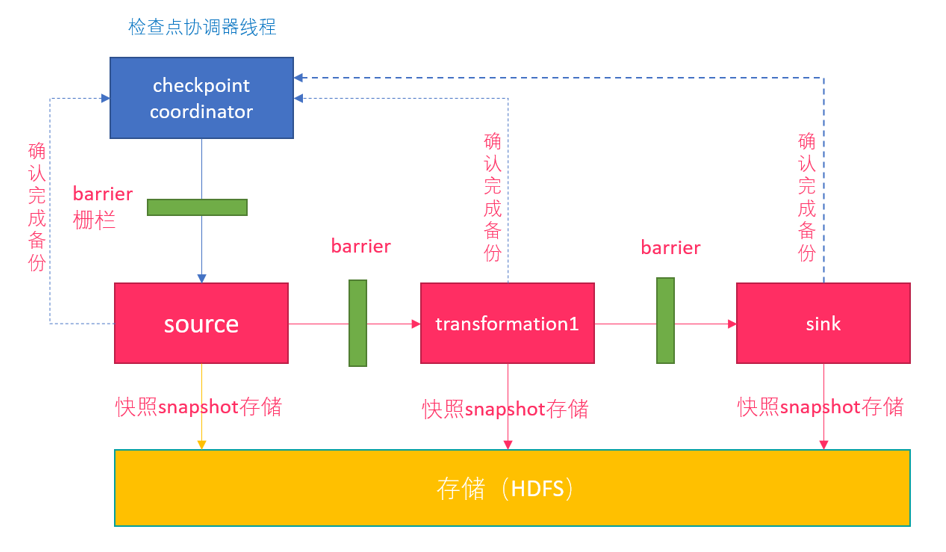
注意:在往介质(如hdfs)中写入快照数据时是异步的(为了提高效率)。
栅栏对齐
栅栏只有在需要提供”精确一次”语义保存时,才需要”栅栏对齐”。如果不需要这种语义,则可以通过配置checkpointMode.AT_LEAST_ONCE关闭”栅栏对齐”来提高性能。
保存点(savepoint)
执行一次savepoint也就是执行一次手动的checkpoint,也就是手动的发一个barrier栅栏,这样的话,程序的所有状态都会被执行快照并保存。
当维护/扩容完毕之后,可以从上一次savepoint的目录中进行恢复。
checkpoint 和 savepoint 区别:
| 比较点 | checkpoint | savepoint |
|---|---|---|
| 触发管理方式 | 由flink自动触发管理 | 由用户手动触发管理 |
| 主要用途 | 在task发生异常时快速恢复 | 有计划地进行备份,使作业能停止后再恢复 |
| 特点 | 轻量、自动从故障中恢复,在作业停止后默认清除 | 持久、以标准格式存储,允许代码或配置发生改变、手动触发从savepoint的恢复 |
触发savepoint:
flink savepoint jobID [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
flink savepoiint jobID -d [targetDirectory] 【-d 是指定位置】
flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
flink run -s savepont [runArgs]
nohup flink run -m yarn-cluster \
-yn 3 -yjm 1024 -ytm 1024 -p 3 \
-s hdfs:/user/root/flink/savepoint-402ba9-e7e4915ab401 \
-c com.sp.writetohbase.writetohbase \
/usr/local/myjob/writetokafka/MyFlinkTTest-1.0-SNAPSHOT.jar &