事务
单个逻辑工作单元执行的一系列操作。
事务的 ACID 属性
- 原子性(Atomicity):要么全部执行,要么全部不执行
- 一致性(Consistency):包装数据的完整性
- 隔离性(Isolation):一个事务的执行不能被其他事务干扰
- 持久性(Durability):事务一旦提交,数据库中数据的改变就是永久的
Java 语言
Java语言是一种特殊的高级语言,它既具有解释型语言的特征,也具有编译型语言的特征。
因为Java程序要经过先编译,后解释两个步骤。
计算机高级语言按程序的执行方式可分为编译型和解释型两种。
编译型语言是指使用专门的编译器,针对特定平台(操作系统)将某种高级语言源代码一次性”翻译”成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。
解释型语言是指使用专门的解释器对原程序逐行解释成特定平台的机器码并立即执行的语言。
Java 程序的运行机制
**Java 程序的执行过程必须经过先编译,后解释两个步骤。**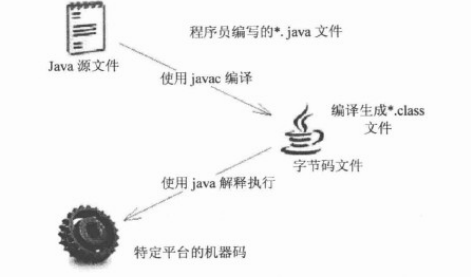
java 语言里负责解释执行字节码文件的是 Java 虚拟机,即 JVM(Java Virtual Machine)。
Java 作用:我们可认为 JVM 分为向上和向下两个部分,所有平台上的 JVM 向上提供给JAVA字节码程序的接口完全相同,但向下适应不同平台的接口则互不相同。
堆和栈
栈内存:栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
堆内存:存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
java 变量
java 变量按照数据类型分类:
基本数据类型(整数、浮点类型、字符型和布尔型)和引用数据类型(类class、接口interface、数组);
java 变量按照声明位置的不同分类:
在方法体外,类体内声明的变量称为成员变量;在方法体内部声明的变量称为局部变量。
java 关键字static
基本概念:
一句话概括:方便在没有创建对象的情况下来进行调用。
即被static关键字修饰的不需要创建对象去调用,直接根据类名就可以访问。
static关键字可以修饰类、方法、变量、代码块。
lzo
启用 lzo 的压缩方式对于小规模集群是很有用处,压缩比率大概能降到日志大小的1/3.同时解压缩的速度也比较快。
宽表
从字面意义上讲就是字段比较多的数据库表。通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。
优点:
- 提高查询性能
- 快速响应
- 方便使用,降低使用成本
- 提高用户满意度
缺点:
- 不符合三范式的模型设计规范,大量数据冗余
- 灵活性差
窄表:严格按数据库设计三范式。尽量减少数据冗余,但缺点是修改一个数据可能需修改多张表。
hive 插入表数据
insert into 语法:
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
insert overwrite 语法:
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
insert overwrite 标准语法的数据来源是通过 select 语法来插入,但为了方便,直接插入 values。
两者异同
同:两者均可以向 hive 表中插入数据
异:insert into 操作是以追加方式向 hive 表尾部追加数据;
insert overwrite 操作是直接重写数据,即先删除 hive 表数据,再执行写入操作。注意,若 hive 表示分区表的话,insert overwrite 操作只会重写当前分区的数据,不会重写其他分区数据。
maven
maven 是 apache 下的一个纯 java 开发的开源项目。基于项目对象模型(缩写:POM)概念,maven 利用一个中央信息片段管理一个项目的构建、报告和文档等步骤。
maven 是一个项目管理工具,可以对 java 项目进行构建、依赖管理。
maven 能够帮助开发者完成以下工作:
- 构建
- 文档生成
- 报告
- 依赖
- SCMs
- 发布
- 分发
- 邮件列表
Java日志框架:slf4j作用及其实现原理
slf4j 只是一个日志标准,并不是日志系统的具体实现。
- 提供日志接口
- 提供获取具体日志对象的方法
slf4j 的用法(常年不变)
Logger logger = LoggerFactory.getLogger(Object.class)
slf4j、log4j、logback关系介绍
Java中static、final、static final的区别
java 接口
接口(interface),在java编程语言中是一个抽象类型,是抽象方法的集合。一个类通过继承接口的方式,从而来继承接口的抽象方法。
接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在java中,接口类型可用来声明一个变量,它们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。
接口与类的区别:
- 接口不能用于实例化对象
- 接口没有构造方法
- 接口中所有的方法必须是抽象方法,java8之后可以使用 default 关键字修饰的非抽象方法
- 接口不能包含成员变量,除了 static 和 final 变量
- 接口不能被类继承,而是被类实现
- 接口支持多继承
java Integer与int
Integer 与 int
java 为每个基本数据类型提供了封装类
为了编程的方便引入了基本数据类型,但是为了将这些基本数据类型当成对象处理,java为每一个基本数据类型都引入了对应的包装类型(wrapper class),int的包装类就是 integer。
基本数据类型:boolean,char,byte,short,int,long,float,double
封装类类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
字符串转换为数字:Integer的parseInt方法
简而言之,将String类型的整数转化成 int 类型的整数。
String s = "100"
int sToInt = Integer.parseInt(s)
java bean 是个什么概念?
注意到,在 maven 项目中,经常遇到 java bean,搜索知乎贴出一个回答。
符合一定规范编写的java类,不是一种技术,而是一种规范。大家针对这种规范,总结了很多开发技巧、工具函数。符合这种规范的类,可以被其他的程序员或者框架使用。
1、 所有属性为 private
2、 提供默认构造方法
3、 提供 getter 和 setter
4、 实现 serializable 接口
java 中 String、StringBuffer 和 StringBuilder 区别
三者的区别主要是在两个方面,即运行速度和线程安全。
1、 运行速度,即执行速度。 StringBuilder > StringBuffer > String
原因:String 为字符串常量,而StringBuilder和StringBuffer均为字符串变量。
2、 线程安全。 StringBuilder 是线程不安全的,而 StringBuffer 是线程安全的。
其他比较好的解释
- String 类是不可变类,即一旦一个 String 对象被创建后,包含在这个对象中的字符序列是不可改变的,直到这个对象被销毁。
- StringBuffer 对象则代表一个字符序列可变的字符串,当一个StringBuffer 被创建以后,提供的 append、insert、reverse、setCharAt、setLength等方法可以改变这个字符串对象的字符序列。一旦生成了最终的字符串,可通过调用 toString 方法将其转换为一个 String 对象。
- StringBuilder 类也代表可变字符串对象。没有实现线程安全功能,性能略高。
isEmpty 和 isBlank 方法
在对字符串进行一些校验(eg:是否为 null、空,是否去掉空格、换行符、制表符等也不为空)通过一些框架工具类去判断,如apache的common jar 包。
1.isEmpty 没有忽略空格参数,是以是否为空和是否存在为判断依据。
2.isBlank 是在 isEmpty 的基础上进行了为空(字符串都为空格、制表符、tab的情况)的判断。(一般更为常用)
JSONObject
JSONObject 只是一种数据结构,可以理解为JSON格式的数据结构(key-value结构),可以使用 put 方法给json对象添加元素。JSONObject 可以很方便的转换成字符串,也可以很方便的将其他对象转换成JSONObject 对象。
JSONObject 接口说明。
java中 JSONObject 与 JSONArray 的使用
JSONObject 的接口
JSONObject 继承自 JSON,JSON 是 Fastjson 的一个主要类,常常需要调用 JSON 的两个方法:
toJSONString(Object):将指定的对象序列化成 JSON 表示形式;
parseObject(String, Class): 将 json 反序列化为指定的 class 模式;
JSONObject 实现了 Map<String, Object>,可见 JSONObject 是一个 Map 类型的数据类型,Map接口提供了很多操作 map 的方法,常用的增删改查。
使用 JSONObject 与 JSONArray
一般取数据有两种方式,看需要选择。
方式①:
通过 JSONObject.getString(“key”) 直接获取,这种方式只能每次获取一个。
方式②:
通过构建与 JSON 对象相应的 bean 来获取。
java Integer类的 byteValue 方法
该方法的作用是以 byte 类型返回该 Integer 的值。只取低八位的值,高位不要。
valueOf() 方法用于返回给定参数的原生 Number 对象值,参数可以是原生数据类型,String等。
flume 自定义拦截器(Interceptor)
使用 flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。
# 编写拦截器类
public class xxx implements Interceptor{
@Override
public void initialize(){
}
# 单个事件拦截
@Override
public Event interceptor(Event event){
……
return enent;
}
# 批量事件拦截
@Override
public List<Event> interceptor(List<Event> list){
……
return list;
}
@override
public void close(){
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new CustomInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
序列化
序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。
在序列化期间,对象将其当前状态写入到临时或持久性存储区。
之后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
Avro
Avro 是 hadoop 的一个数据序列化系统,由hadoop的创始人Doug Cutting 开发,设计用于支持大批量数据交换的应用。它的主要特点有:
- 支持二进制序列化方式,可以便捷、快速的处理大量数据
- 动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据