首先对文件关联进行设置
# 在普通用户 hadoop 中设置
sudo chown -R hadoop ./hadoop
sudo chown -R hadoop ./flume
sudo chown -R hadoop ./kafka
sudo chown -R hadoop ./zookeeper
hadoop搭建
参数调优
1) HDFS 参数调优 hdfs-site.xml
-
dfs.namenode.handler.count = 20 *log2(Cluster Size),如集群规模为10台时,该参数设置为60.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。 -
编辑日志存储路径 dfs.namenode.edits.dir 设置与镜像文件存储路径 dfs.namenode.name.dir 尽量分开,达到最低写入延迟。
2) YARN 参数调优 yarn-site.xml
(1) 情境描述:总共7台机器,每天几亿条数据,数据源->Flume->kafka->HDFS->Hive
面临问题:数据统计主要用 hiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的 JVM 重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2) 解决方法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小和hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
-
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192MB,注意,如果你的节点内存资源不够8GB,则需要调减这个值,而YARN不会智能的探测节点的物理内存总量。
-
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192MB。
(3) Hadoop 宕机
- 如果MR造成系统宕机。此时要控制YARN同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
- 如果写入文件过量造成NameNode宕机。那么调高 kafka 的存储大小,控制从kafka到HDFS的写入速度。高峰期的时候用kafka进行缓存,高峰期过去数据同步会自动跟上。
zookeeper 搭建
配置 zoo.cfg 文件
增加 cluster 的配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
配置参数解读 server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在 dataDir目录下,这个文件里面有一个数据就是A的值,启动时读取该文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server.
B 是这个服务器的 ip 的地址
C 是这个服务器与集群中的 Leader 服务器交换信息的端口
D 是万一集群中的 leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# 查看 zk 启动错误原因
cd /usr/local/zookeeper/bin
./zkServer.sh start-foreground
# 用户:hadoop zk 启动停止脚本
mkdir bin
sudo vim zk.sh
#!/bin/bash
case $1 in
"start"){
sudo ssh 192.168.184.131 "/usr/local/zookeeper/bin/zkServer.sh start"
};;
"stop"){
sudo ssh 192.168.184.131 "/usr/local/zookeeper/bin/zkServer.sh stop"
};;
"status"){
sudo ssh 192.168.184.131 "/usr/local/zookeeper/bin/zkServer.sh status"
};;
esac
# 增加脚本执行权限
chmod 777 zk.sh
日志生成
# 上传jar包
cd /usr/local/module
logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar
# 执行jar程序
java -classpath logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.java.appclient.AppMain > /usr/local/module/test.log
# 查看日志文件,注意这个日志输出地址与日志生成代码中 logback.xml 的 LOG_HOME 相关。
cd /tmp/logs/
cat app-2021-10-30.log
# 日志生成脚本
cd bin
sudo vim lg.sh
#!/bin/bash
ssh 192.168.184.131 'java -classpath /usr/local/module/logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.java.appclient.AppMain > /usr/local/module/test.log &'
sudo chmod 777 lg.sh
# 集群时间同步
cd bin
sudo vim dt.sh
#!/bin/bash
log_date=$1
ssh -t 192.168.184.131 "sudo date -s $log_date"
sudo chmod 777 dt.sh
# 启动脚本
dt.sh 2019-2-10
date
flume(日志收集) 搭建
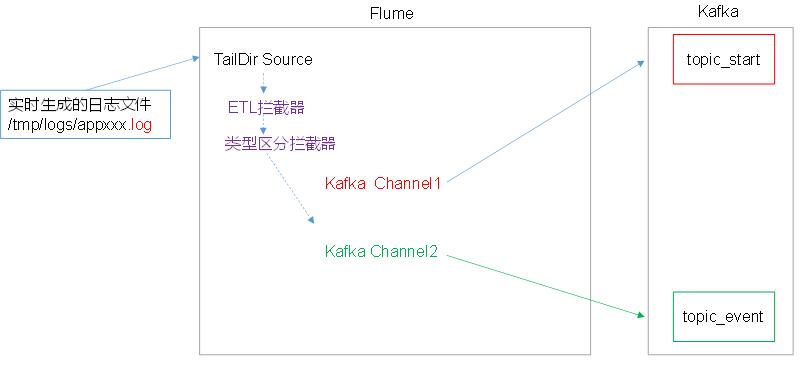
Source
- TaildirSource 相比 Exec Source、Spooling Directory Source 的优势
TaildirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
Exec Source:可以实时搜索数据,但是在Flume 不运行或者shell 命令出错的情况下,数据将会丢失。
Spooling Directory Source:监控目录,不支持断点续传。 - batchSize 大小如何设置?
Event 1K左右时,500-1000合适(默认是 100)
Channel
采用 kafka channel,省去了sink,提高了效率。
这里使用 kafaChannel,具体的kafkaChannel说明,可见技术选型中的 flume 中说明。
file-flume-kafka.conf
# 组件定义
a1.sources=r1
a1.channels=c1 c2
a1.sources.r1.type=TAILDIR
# 记录文件索引节点的目录,实现断点续传
a1.sources.r1.positionFile=xxx
a1.sources.r1.filegroups=f1
a1.sources.r1.filegroups.f1=/tmp/logs/app.+
a1.sources.r1.fileHeader=true
# 拦截器(ETL 拦截器与类型区分拦截器)
a1.sources.r1.interceptors=i1 i2
a1.sources.r1.interceptors.i1.type=com.gree.flume.interceptors.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type=xxx
# channel 选择器
a1.sources.r1.selector.type=multiplexing
a1.sources.r1.selector.header=topic
a1.sources.r1.selector.mapping.toipc_start=c1
a1.sources.r1.selector.mapping.toipc_event=c2
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers=xxx
a1.channels.c1.kafka.topic=topic_start
a1.channels.c1.parseAsFlumeEvent=false
a1.channels.c1.kafka.consumer.group.id=flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
kafka搭建
kafka 机器数量计算
kafka 机器数量(经验公式) = 2(峰值生成速度×副本数/100) + 1先要预估一天大概生产多少数据,然后用 kafka 自带的生产测压(只测试 kafka 的写入速度,保证数据不积压),计算出峰值生产速度。再根据设定的副本数,就能预估出需要部署 kafka 的数量。
如我们采用压力测试测出写入的速度是 10M/s 一台,峰值的业务数据的速度是 50M/s。副本数为2。
则 kafka 机器数量 = 2(50×2/100) + 1 =3 台
kafka 的启动停止脚本
vim kf.sh
#!/bin/bash
case $1 in
"start"){
sudo ssh 192.168.184.131 "/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties "
};;
"stop"){
#kill -9 $(jps -l | grep 'kafka\.Kafka' | awk '{print $1}')
#kill -s KILL $(jps -l | grep 'kafka\.Kafka' | awk '{print $1}')
sudo ssh 192.168.184.131 "/usr/local/kafka/bin/kafka-server-stop.sh stop"
};;
esac
注意到:在使用脚本停止 kafka 时,显示错误:无法关闭。因此,需要修改 kafka-server-stop.sh。
PIDS=$(/usr/java/jdk1.8.0_162/bin/jps -l | grep 'kafka\.Kafka' | awk '{print $1}')
kill -s KILL $PIDS
flume(消费 kafka)搭建
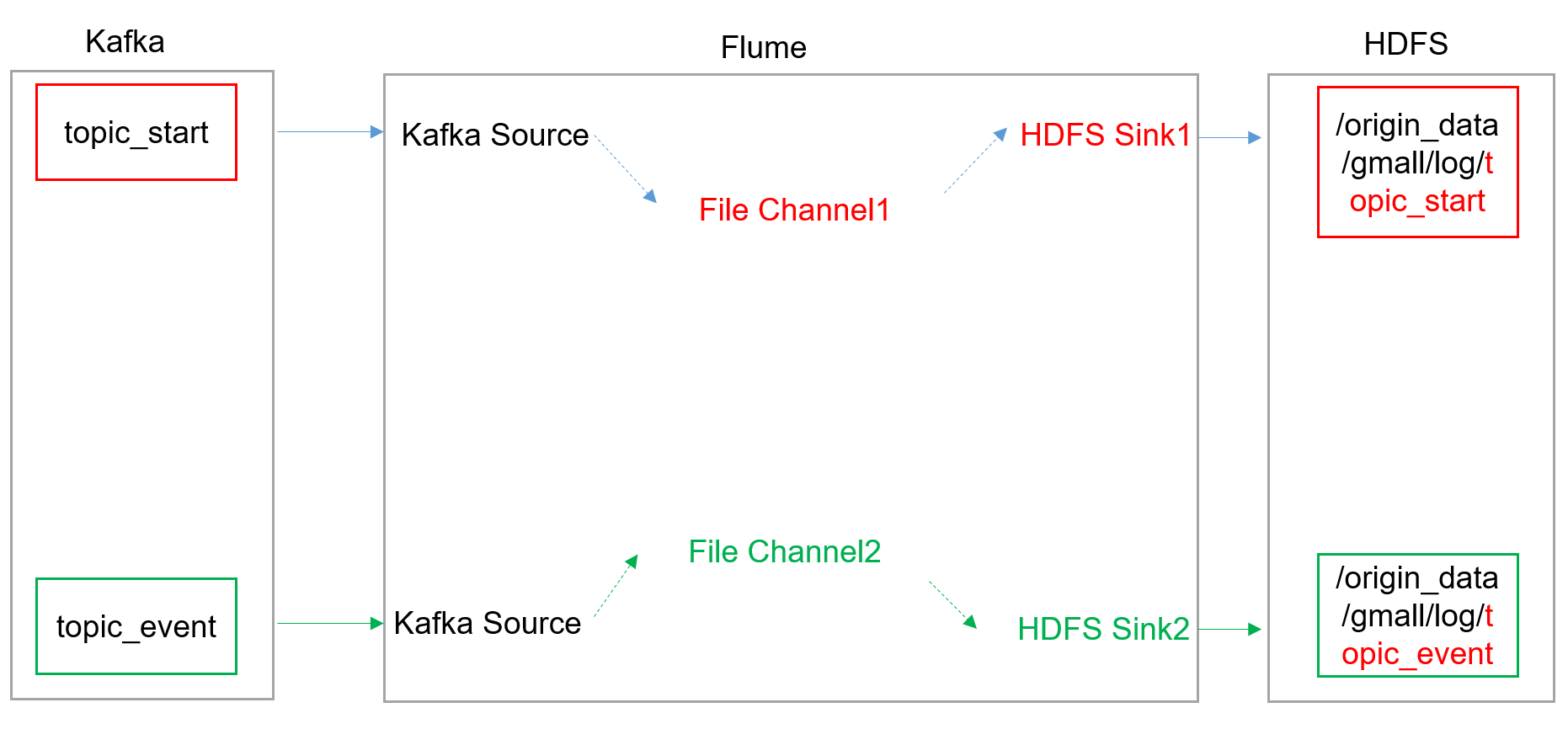
flume 内存优化
问题描述: ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limitexceeded
解决方案步骤:在/usr/local/flume/conf/flume-env.sh中,增加配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
flume内存参数设置及优化:
JVM heap 一般设置为4G或更高,部署在单独的服务器上(4核8线程16G内存)
-Xmx 与 -Xms 最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
flume组件
- FileChannel和MemoryChannel区别
MemoryChannel 传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
FileChannel 传输速度相对于 Memory 慢,但是数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。 - FileChannel优化
通过配置 dataDirs 指向多个路径,每个路径对应不同的硬盘,增大flume吞吐量。
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用 backupCheckpointDir恢复数据。 - sink: HDFS sink
HDFS 存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在 namenode 内存中,所以小文件过多,会占用 namenode 服务器大量内存,影响 namenode 性能和使用寿命。
计算层面:默认情况MR会对每个小文件启用一个 Map 任务计算,非常影响计算性能,同时也影响磁盘寻址时间。
HDFS小文件处理 官方默认的三参数配置写入HDFS后会产生小文件, hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
基于hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount=0,hdfs.roundValue=10,hdfs.roundUnit= second 几个参数综合作用,效果如下:
(1) tmp文件在达到128M时会滚动生成正式文件
(2) tmp文件创建超10秒时会滚动生成正式文件