zookeeper 是一个分布式的、开放源码的分布式应用程序协调服务,是hadoop和hbase的重要组件。
分布式应用程序可以基于 zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
说明:这里的记录基于菜鸟教程。
zookeeper 教程
相关 CAP 理论
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
- 可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
- 分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availablity)和分区容错性(Partition tolerance)这三项中的两项。
zookeeper 保证的 CP。
BASE 理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态)和Eventually Consistent(最终一致性)三个短语的缩写。
- 基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)
- 软状态:允许分布式系统出现中间状态。这里的中间状态是指不同的data replication之间的数据更新可以出现延时的最终一致性。
- 最终一致性: data replications(数据备份节点)经过一段时间达到一致性。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
zookeeper 安装
安装过程较简单。
服务端和客户端的启动:
cd bin
sh zkServer.sh start
sh zkClient.sh
启动客户端,出现”welcome to ZooKeeper”表示启动成功。
zookeeper linux 服务端集群搭建
说明,在 zoo.cfg 配置信息
server.1=192.168.3.33:2888:3888
server.2=192.168.3.35:2888:3888
server.3=192.168.3.37:2888:3888
zookeeper 的三个端口作用:
- 2181:对client端提供服务
- 2888:集群内机器通信使用
- 3888:选举 leader 使用
数据模型 znode 结构
在 zookeeper 中,可以说 zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以key/value形式存储数据。
整体结构类似于 linux 文件系统的模式以树形结构存储,其中根路径以 / 开头。
sh zkClient.sh
ls /
ls /
ls /zookeeper
zookeeper session 基本原理
客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就是 session 会话。
从第一次连接建立开始,客户端开始会话的声明周期,客户端向服务端的 ping 包请求,每个会话都可以设置一个超时时间。
会话超时管理(分桶策略 + 会话激活)
zookeeper 的 leader 服务器再运行期间定时进行会话超时检查,时间间隔是 ExpirationInterval,单位是毫秒,默认值是 tickTime,每隔 tickTime 进行一次会话超时检查。
ExpirationTime 的计算方式:
ExpirationTime = CurrentTime + SessionTimeout
ExpirationTime = (ExpirationTime / ExpirationInterval + 1)* ExpirationInterval
在 zookeeper 运行过程中,客户端会在会话超时过期范围内向服务器发送请求(包括读和写)或者 ping请求,俗称心跳检测完成会话激活,从而来保持会话的有效性。
zookeeper 客户端基础命令使用
# 打开新的 session 会话,进入终端
sh zkClient.sh
# 查看某个路径下目录列表
ls path
# 查看某个路径下目录列表,较ls 命令列出更多的详细信息
ls2 path
# 获取节点数据和状态信息,watch 对节点进行事件监听
get path[watch]
# 节点状态信息
stat path[watch]
# 创建节点并赋值
create -s -e /runoob 0
# 修改节点存储的数据
set path data[version]
# 删除某节点
delete path[version]
四字命令
# 查看当前 zkServer 是否启动
echo ruok | nc xxx.xxx 2181
# 列出未经处理的会话和临时节点
echo dump | nc xxx.xxx 2181
# 查看服务器配置
echo conf | nc xxx.xxx 2181
# 展示连接到服务器的客户端信息
echo cons | nc xxx.xxx 2181
# 查看环境变量
echo envi | nc xxx.xxx 2181
zookeeper 节点特性
- 同一级节点 key 名称是唯一的
- 创建节点时,必须要带上全路径
- session 关闭,临时节点清楚
- 自动创建顺序节点
- watch 机制,监听节点变化
- delete 命令只能一层一层删除(新版本通过deleteall命令递归并删除)
zookeeper 权限控制 ACL
ACL(Access Control List, 访问控制表)权限可以针对节点设置相关读写等权限,保障数据安全性。
ACL 命令行
- getAcl 命令:获取某个节点的 acl 权限信息
- setAcl 命令:设置某个节点的 acl 权限信息
- addauth 命令:输入认证授权信息,注册时输入明文密码,加密形式保存
ACL 构成
zookeeper 的 acl 通过[scheme:id:permissions]来构成权限列表。
- scheme:代表采用的某种权限机制,包括 world、auth、digest、ip、super几种。
- id:代表允许访问的用户
- permissions:权限组合字符串,由 c(创建)d(删除)r(读)w(写)a(管理权限) 组成。
zookeeper watcher 事件机制原理剖析
zookeeper 的 watcher机制,可以分为四个过程:
- 客户端注册 watcher
- 服务端处理 watcher
- 服务端触发 watcher 事件
- 客户端回调 watcher
zookeeper 数据同步流程
在zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。
ZAB 协议分为两部分:
- 消息广播
- 崩溃恢复
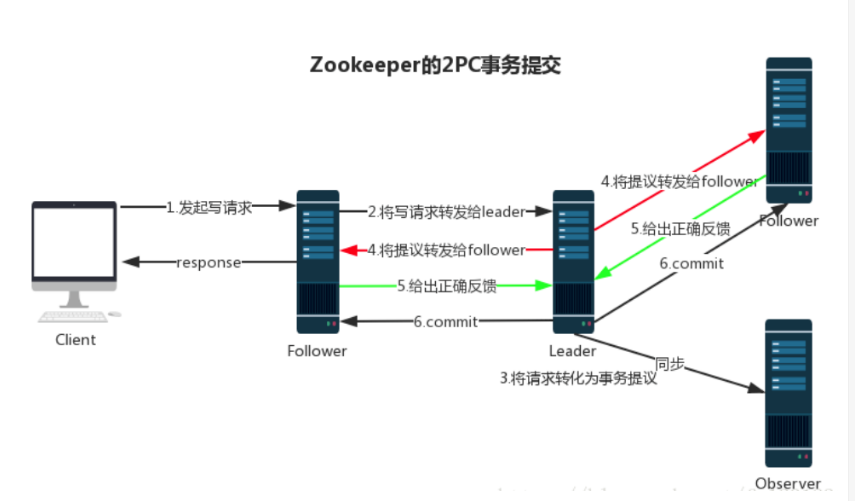
Zookeeper 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的Follower 服务器进行正确的 ACK 反馈,那么Leader就会再次向所有的 Follower 服务器发送commit 消息,将此次提案进行提交。这个过程可以简称为 2pc 事务提交,整个流程可以参考下图,注意 Observer 节点只负责同步 Leader 数据,不参与 2PC 数据同步过程。
进入崩溃恢复模式:leader 服务器出现崩溃,网络原理导致leader服务器失去了与过半 follow 的通信。在选举新的leader 服务器的过程中,可能会出现两种数据不一致性的隐患。需使用 ZAB 协议特性进行避免。
- leader 服务器将消息 commit 发出后,立即崩溃
- leader 服务器刚提出 proposal 后,立即崩溃
ZAB 协议的恢复模式使用了以下策略:
- 选举 zxid 最大的节点作为新的 leader
- 新 leader 将事务日志中尚未提交的消息进行处理
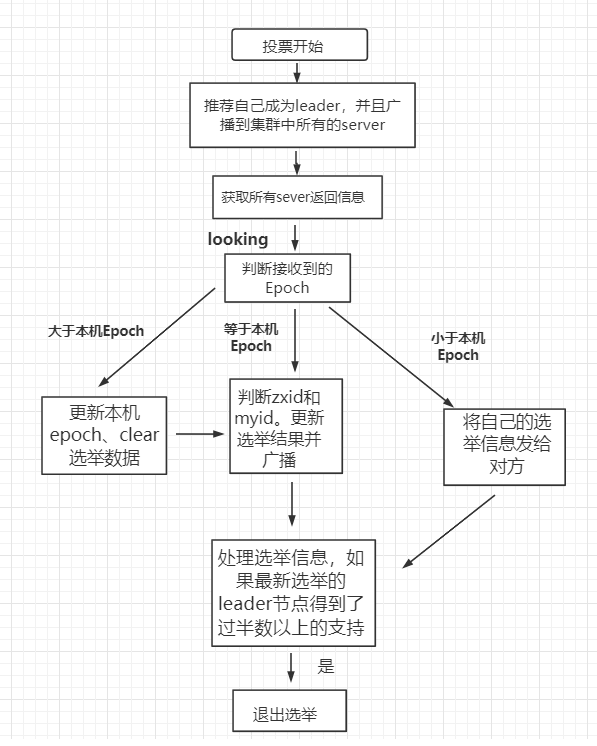
zookeeper leader 选举原理
选举过程中,有几个重要的参数:
-1. 服务器ID(myid):编号越大在选举算法中权重越大
-2. 事务ID(zxid):值越大说明数据越新,权重越大
-3. 逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投一次值会增加。
zookeeper 分布式锁实现
排他锁,又被称为写锁或独占所。
共享锁,又称为读锁。