Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,是伯克利分校的 AMP 实验室所开源的类 Hadoop MapReduce 的通用并行框架。
spark,拥有 Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是 ——— Job 中间输出结果可以保存在内存中,从而不再需要读写 HDFS,因此spark能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 算法。
区别
【spark 较 hadoop 快】
因为上述链接已给出了一些回答,下面简单总结下:
| 区别 | spark | mapreduce |
|---|---|---|
| 内存 vs 磁盘 | 不需将计算中间结果写入内存(由于RDD和DAG) | 计算的中间结果写入磁盘,还需读取磁盘,导致了频繁的磁盘IO |
| shuffle不同 | 仅在部分场景中才需排序,支持基于Hash的分布式聚合 | 花费大量时间进行排序 |
| 多进程模型 vs 多线程模型 | 复用线程池中的线程来减少启动关闭task所需开销,但会发生资源争用 | 采用多进程模型,会消耗一定的启动时间 |
单机安装
在centos7 中安装 spark,需下载:
scala-2.11.12.tgz
spark-2.4.4-bin-without-hadoop.tgz
scala 的安装
tar -zxvf scala-2.11.12.tgz -C /usr/local
cd /usr/local/scala
mv scala-2.11.12 scala
vim /etc/profile
# ADD scala path
export SCALA_HOME=/usr/local/scala
export PATH=${SCALA_HOME}/bin
source /etc/profile
# verfity
scala -version
spark 的安装
tar -zxvf spark-2.4.4-bin-without-hadoop.tgz /usr/local
cd /usr/local/spark
mv spark-2.4.4-bin-without-hadoop spark
vim /etc/profile
# ADD spark path
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/bin
source /etc/profile
cd /usr/local/spark/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export JAVA_HOME=/usr/java/jdk1.8.0_162
export HADOOP_HOME=/usr/local/hadoop
#export HIVE_CONF_DIR=/usr/local/hive/conf
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=aubin.com
export SPARK_WORKER_MEMORY=512M
# verfity
./bin/spark-shell
dirver 和 executor的理解
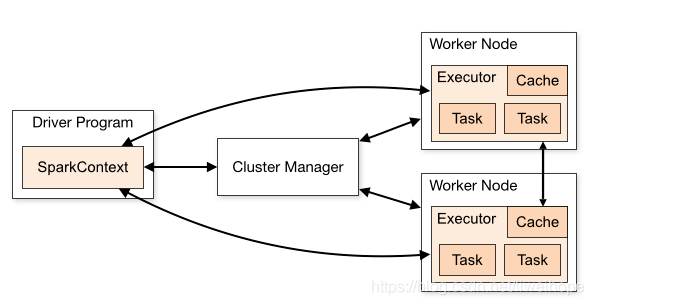
spark模式比较
spark 主要有四种运行模式: Local、standalone、yarn、mesos。
| 模式 | 解释 | sparkshell |
|---|---|---|
| local | 在一台机器上,一般用于开发测试 | ./spark-shell -master local[2] |
| standalone | 完全独立的spark集群,不依赖其他集群 | ./spark-shell –master spark://xxx:70077 |
| yarn | 依赖hadoop集群,yarn资源调度框架,将应用提交至yarn | ./spark-shell –master yarn |
| mesos | 类似yarn模式,运行在mesos集群上 | ./spark-shell –master mesos |
这里简单说明下,基于 Yarn-cluster 模式提交任务的原理图解。
./spark-submit --master yarn --deploy-mode cluster --class jar...
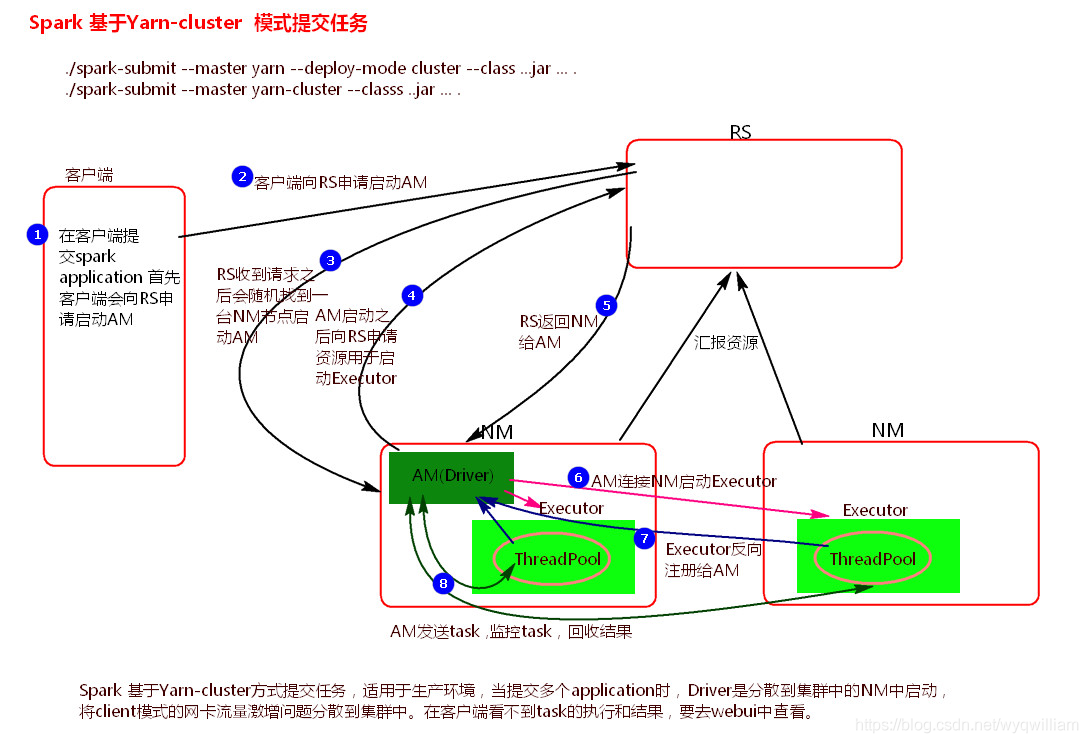
执行流程如下:
- 客户机提交 application 应用程序,发送请求到RM(ResourceManager),请求启动AM(ApplicationMaster);
- RM 接收到请求后随机在一台 NM(NodeManager)上启动 AM(相当于Driver 端);
- AM 启动,AM发送请求到 RM,请求一批 container 用于启动 executor;
- RM 返回一批 NM 节点给 AM;
- AM 连接到NM,发送请求到 NM启动 executor;
- executor 反向注册到 AM 所在节点的Driver。Driver发送 task 至 executor。
spark-submit 提交作业参数说明
注意:在集群中设置了 kerberos 网络权限协议,在提交spark作业时,需提供参数 –keytab 与 –principal,具体可见链接。
| 参数 | 说明 |
|---|---|
| –master | 集群的 master 地址 |
| –deploy-mode | driver运行模式,client或cluster模式 |
| –class | 应用程序主类 |
| -–executor-memory | 每个executor 的执行内存 |
| -–executor-cores | 分配给每个executor的内核数 |
| –num-executor | executor的数量(仅yarn) |
| –keytab | 包含keytab文件的全路径(仅yarn) |
| –principal | 运行于secure hdfs 时用于登录到KDC的principal |
方法一:通过配置参数的方式访问
val spark = SparkSession.builder().appName("OfflineSpark")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.hadoopConfiguration.set("fs.defaultFS", "hdfs://cdhservice")
sc.hadoopConfiguration.set("dfs.nameservices", "cdhservice")
sc.hadoopConfiguration.set("dfs.ha.namenodes.cdhservice", "namenode36,namenode105")
sc.hadoopConfiguration.set("dfs.namenode.rpc-address.cdhservice.namenode36", "cdh1:8020")
sc.hadoopConfiguration.set("dfs.namenode.rpc-address.cdhservice.namenode105", "cdh3:8020")
sc.hadoopConfiguration.set("dfs.client.failover.proxy.provider.cdhservice", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider")
val data = sc.textFile("hdfs://cdhservice/user/tescomm/data/install.log")
data.foreach(println)
val druiddata = spark.read.parquet("hdfs://cdhservice/user/tescomm/data/16th").limit(10)
druiddata.show()
方法二:通过配置文件访问:
val spark = SparkSession.builder().appName("OfflineSpark")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.hadoopConfiguration.addResource("cdhservice/core-site.xml")
sc.hadoopConfiguration.addResource("cdhservice/hdfs-site.xml")
val data = sc.textFile("hdfs://cdhservice/user/tescomm/data/install.log")
data.foreach(println)
val druiddata = spark.read.parquet("hdfs://cdhservice/user/tescomm/data/16th").limit(10)
druiddata.show()
小结
spark 有三大引擎,spark core、sparkSQL、sparkStreaming
spark core 的关键抽象是 SparkContext、RDD
SparkSQL 的关键抽象是 SparkSession、DataFrame
sparkStreaming 的关键抽象是 StreamingContext、DStream
SparkSession 是 spark2.0 引入的概念,主要用在 sparkSQL 中,当然也可以用在其他场合,它可以代替 SparkContext; SparkSession 其实是封装了 SQLContext 和 HiveContext
bugs
- Error: A JNI error has occurred, please check your installation and try again
【原因】:缺少 hadoop 依赖包
【解决方法】:spark-env.sh 中添加 hadoop 的 classpath 至 SPARK_DIST_CLASSPATH中
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) - Exception in thread “main” java.lang.NoSuchMethodError: jline.console.completer.CandidateListCompletionHandler.setPrintSpaceAfterFullCompletion(Z)V
【原因】:缺少 jline jar 依赖包
【解决方法】:将 scala 的jar文件中的 jline.jar 复制至 spark 所在的 jar 包中 - 其他问题
