kafka是一种高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。
主要应用场景是:日志收集系统和消息系统。
kafka与zookeeper关系:通过 zookeeper 管理集群配置,选举 leader,以及在 consumer group发生变化时进行 rebalance。
zookeeper 作用:管理 broker、consumer,将元数据信息保存在 zookeeper 中。
producer:使用 push 模式将消息发布到 broker
consumer:使用 pull 模式从 broker 订阅并消费消息
基于 kafka 与 zookeeper 的关系,因此zookeeper的使用可以单独安装,也可以使用 kafka 自带的。
这里,我们单独安装zookeeper,因为其他组件,如 hbase 在实现 HA 选举与主备集群主节点的切换等于 zk 有关系。
单机安装
需下载组件
apache-zookeeper-3.7.0-bin.tar.gz
kafka_2.11-0.10.1.0.tgz
# zk
sudo tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/
sudo mv apache-zookeeper-3.7.0-bin.tar.gz zookeeper
sudo chown -R hadoop:hadoop zookeeper
cp zoo_sample.cfg zoo.cfg
sudo vim zoo.cfg
dataDir=/usr/local/zookeeper/data
# zk 启动
./bin/zkServer.sh start
./bin/zkServer.sh status
# 通过查看 zk 进程确定启动成功与否
ps -ef | grep zookeeper
# 还可以设置 zk 开机自启动
sudo vim zookeeper
``
#!/bin/bash
#chkconfig:2345 20 90
#description:zookeeper
#processname:zookeeper
ZK_PATH=/usr/local/zookeeper
export JAVA_HOME=/usr/java/jdk1.8.0_162
case $1 in
start) sh $ZK_PATH/bin/zkServer.sh start;;
stop) sh $ZK_PATH/bin/zkServer.sh stop;;
status) sh $ZK_PATH/bin/zkServer.sh status;;
restart) sh $ZK_PATH/bin/zkServer.sh restart;;
*) echo "require start|stop|status|restart" ;;
esac
``
# 在 root用户 下操作,添加执行权限
su root
chmod +x zookeeper
# 添加到开机权限
chkconfig --add zookeeper
# kafka
sudo tar -zxvf kafka_2.11-0.10.1.0.tgz -C /usr/local/
sudo mv kafka_2.11-0.10.1.0.tgz kafka
sudo chown -R hadoop:hadoop kafka
sudo vim ./config/server.properties
``
zookeeper.connect=192.168.184.131:2181
``
测试
sudo service zookeeper start
# 查看状态
ps -ef | grep zookeeper
nohup ./bin/kafka-server-start.sh ./config/server.properties &
# 创建新 topic
./bin/kafka-topics.sh --create --zookeeper 192.168.184.131:2181 --replication-factor 1 --partitions 1 --topic test
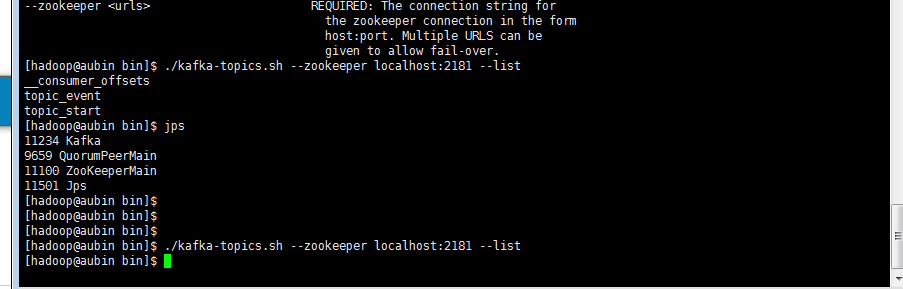
# 查看 topic
./bin/kafka-topics.sh --list --zookeeper xxx:2181
# 产生消息
./bin/kafka-console-producer.sh --broker-list xxx:9092 --topic test
# 消费消息
# 0.8 版本及以下的kafka使用如下命令
./bin/kafka-console-consumer.sh --zookeeper xxx:2181 --topic test --from-beginning
# 0.9 版本及以上kafka建议使用以下命令进行消费,
./bin/kafka-console-consumer.sh --bootstrap-server xxx:9092 --topic test --from-beginning
kafka 全部数据清空
首先,停止kafka进程:
kill -9 PID
其次,删除存储目录:
cat server.properties
log.dirs=xxx
rm -rf xxx/kafka-logs/*
再次,删除zookeeper上与kafka相关的znode(zookeeper 上保存着 kafka 的所有topic及其消费信息):
cd /usr/local/zookeeper/bin
./zkCli.sh -server localhost:2181
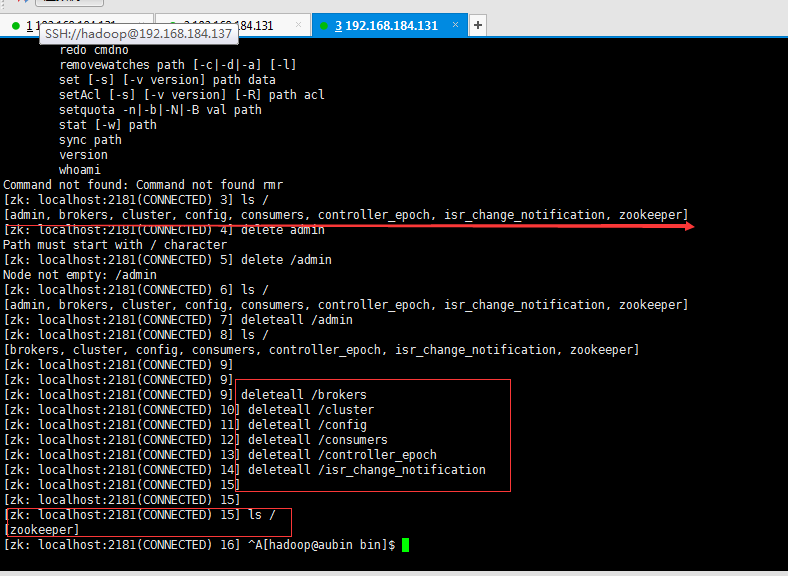
重启kafka:
cd /usr/local/kafka
./bin/kafka-server-start.sh ./config/server.properties
kafka 删除 topic
彻底删除 kafka 中的 topic marked for deletion
# 删除命令
./kafka-topics --delete --zookeeper {zookeeper server} --topic {topic name}
此时,显示 marked for deletion.
除了一般的删除/tmp/kafka_logs和设置 delete.topic.enable=true,有时我们需要在 zookeeper client中删除对应的节点.
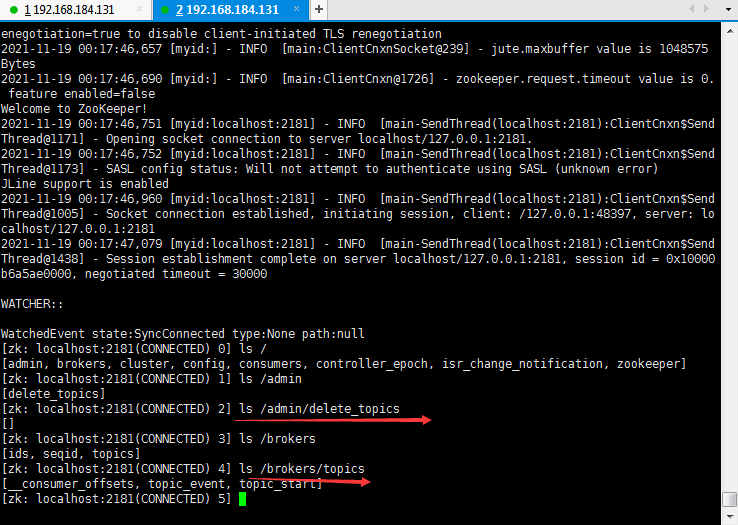
使用命令
deleteall /admin
deleteall /brokers
保留主题只删除主题数据log
生产环境中,有topic数据量非常大,这些数据不是非常重要,需要定期清理。
清除方式主要有3个:基于时间;基于日志大小;基于日志起始偏移量。
server.properties 为全局策略配置文件(针对每一个topic):
# 启用删除主题
delete.topic.enable=true
# 检查日志段文件的间隔时间,以确定是否文件属性达到删除要求
log.retention.check.interval.ms=1000000
测试过程
设置清除策略保留位10s。
-1. 设置策略
./kafka-configs.sh --zookeeper xxx:2181 --entity-type topics --entity-name test --alter --add-config retention.ms=10000
-2. 查看topic策略
./kafka-configs.sh --zookeeper xxx:2181 --describe --entity-type topics --entity-name test
-3. 生产者生产数据
./kafka-console-producer.sh --broker-list xxx:9092 --topic test
-4. 消费者消费数据
./kafka-console-consumer.sh --bootstrap-server xxx:9092 --topic test --from-beginning

生产者和消费者
# 创建生产者
Properties props = new Properties()
props.put("bootstrap.servers","xxx:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer")
Producer<String, String> producer = new KafkaProducer<>(props)
# 构造 ProducerRecord
ProducerRecord<String, String> record = new ProducerRecord<>("topic", "key", "value")
# 发送消息至broker
# 方法1:发送即忘
producer.send(record)
# 方法2:同步发送
RecordMetadata rm = producer.send(record).get()
# 方法3:异步发送(一般选择这种)
producer.send(record, new Callback()){
public void onCompletion(RecordMetadata rm,Exception e)
}
# 创建消费者
Properties props = new Properties()
props.put("bootstrap.servers","xxx:9092")
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
props.put("group.id", "xxx")
Consumer<String, String> consumer = new KafkaConsumer<>(props)
# 订阅主题
# 订阅固定的 topic
consumer.subscribe(Collection.singletonList("xxx"))
# 动态订阅
consumer.subscribe("gp.*")
# 轮询
try{
while(true){
ConsumerRecords<String,Customer> records = consumer.poll(100)
for(ConsumerRecords<String,Customer> r:records){
System.out.printf("offset=%d,key=%s,value=%s%n", r.offset(),r.key(),r.value())
}
}
}finally{
consumer.close()
}
seek 方法
消息的拉取根据 poll 方法来处理,但该方法中的逻辑对开发人员而言是一个黑盒,无法精准地掌控消费的起始位置,参数 auto.offset.reset 只是粗粒度从开头或末尾开始消费。有时候,我们需要一种更细粒度的掌控,可让我们从特定的位移处开始拉取消费,kafka consumer中的seek方法具有该功能。
seek方法只能重置消费者分配到的分区的消费位置,而分区的分配是在poll方法的调用过程中实现的。也就是说,在执行seek()方法之前需要先执行一次poll方法, 等到分配到分区之后才可以重置消费位置(如果用subscribe订阅的话就需要poll一次,如果用assign()手动订阅分区就不需要poll一次)。
acks 参数
多副本冗余机制:topic 的分区 partition 有一个副本是leader,另一个是Follower,分布在不同机器上,可保证在一台机器挂掉,不会导致数据彻底丢失。
多副本数据同步:任何一个partition,只有leader对外提供读写服务,leader接收到数据后,follower 副本会不停的给他发送请求尝试拉取最新数据至本地磁盘。
ISR(In-Sync Replica):是replicas的一个子集,表示目前alive与leader能够 catch-up的replicas集合。
acks参数:
acks = 0:kafkaProducer在客户端将消息发送出去,不管发送出去的数据有无同步完成,直接就认为该消息发送成功。其提供了最低的延迟,但持久性最差。
acks = 1(默认):只要partition leader接收到消息而且写入本地磁盘,就认为成功了,不管其他follower有没有同步过去该条消息。其提供了较好的持久性较低的延迟。
acks = all:partition leader 接收到消息后,还必须要求ISR列表中跟leader保持同步的那些follwer都要把消息同步过去,才能认为该条消息写入成功。
???acks = all 是否意味着数据一定不会丢失?
答案是否定的。若partition 只有一个副本,接收消息后宕机,也会导致数据丢失。因此,ISR列表至少有2个以上的副本才可以。
bugs
# 报错
cd /usr/local/kafka
./bin/kafka-topics.sh --zookeeper localhost:2181 --list
# 观察到 config/server.properties 中的 zookeeper.connect 设置为 IP:2181
./bin/kafka-topics.sh --zookeeper IP:2181 --create --topic test --partitions 3 --replication-factor 3
- Client port found: 2181. Client address: localhost. Client SSL: false. Error contacting
改安装 apache-zookeeper-3.7.0-bin.tar.gz 解决。 - /OPT/MODULE/KAFKA/BIN/KAFKA-RUN-CLASS.SH: 第 258 行:EXEC: JAVA: 未找到
# 设置kafka 的启动脚本
#!/bin/bash
case $1 in
"start"){
sudo ssh 192.168.184.131 "/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties "
};;
"stop"){
sudo ssh 192.168.184.131 "/usr/local/kafka/bin/kafka-server-stop.sh stop"
};;
esac
通过设置软链接:
ln -s /usr/java/jdk1.8.0_162/bin/java /usr/bin/java