impala 是大数据分析引擎,分为以下3部分进行记录说明。
- impala概念与架构
- impala 资源管理
- impala 性能优化
impala 概念与架构
impala 简介
- impala 基于 google 的Dremel 为原型的查询引擎,由 cloudera 推出,能查询存储在 hadoop 的HDFS和HBase的PB级大数据,具有高性能、低延迟的交互式SQL查询功能。
- impala 服务器是一个分布式,大规模并行处理(MPP)的服务引擎。
-
基于hive使用内存计算
,兼顾数据仓库,具有实时、批处理、多并发等优点。
- 是 CDH 平台首选的PB级大数据实时查询分析引擎。
SMP 与 MPP
SMP(Symmetric Multi Processing,share everything):对称多处理器结构,所有的CPU共享全部资源。操作系统或管理数据库的复本只有1个。增加节点并不会使得资源呈线性增加。
MMP(Massively Parallel Processing,share nothing):海量并行处理,由许多松耦合的处理单元(非处理器)组成,这里的处理单元内的CPU都有自己私有的资源。在每个单元内都有操作系统和管理数据库的实例复本。
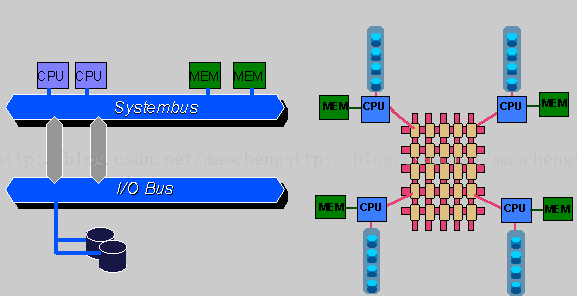
impala 核心组件
Statestore Daemon- 负责收集分布在集群中各个 impalad 进程的资源信息、各节点健康状况,同步节点信息。
- 负责 query 的调度
- 分发表的元数据信息到各个 impalad 中
- 接收来自 statestore 的所有请求
- 接收 client、hue、jdbc或者odbc请求、Query 执行并返回给中心协调节点子节点上的守护进程,负责向 statestore 保持通信,汇报工作。
Impala 的架构,见下图:
Impala 自身包含三个模块: Impalad、Statestore(存放 hive 的元数据)和 catalog(拉取真实数据),除此之外它还依赖 hive metastore 和 HDFS。
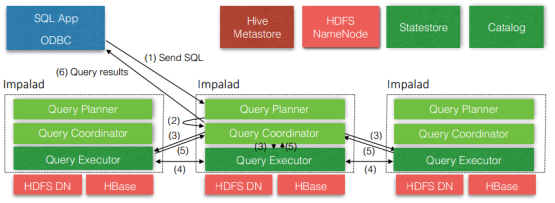
Query Executor 与 Query Coordinator 分开安装,Query Executor 放在多台服务器上。
impala 的优势
详细可点击链接查看,这里列举几条:
- impala 不需要将中间结果写入磁盘,省掉了大量的I/O开销;
- 省去了MR作业启动的开销;
- 通过使用 LLVM 来统一编译运行时代码,避免了为支持通用编译带来的不必要开销。
impala 资源管理
静态资源池
使用静态资源池可以给 impala 和其他服务分配专用的资源,以考虑到预计的资源需求。静态资源池将服务彼此隔离开来。
动态资源池
动态资源池是用来配置及用于在池中运行的 YARN 应用程序或 impala 查询之间安排资源的策略。动态资源池允许你基于用户访问指定池的权限,调度和分配资源给 impala的查询使用。
资源管理相关参数设置
REQUEST_POOL:可将查询语句提交到不同的资源池,如 set request_pool=impala;
MEM_LIMIT:可以解决impala对复杂查询的内存消耗估算不准确的问题;
EXPLAIN_LEVEL:设置执行计划显示的详细程度;
COMPUTE STATS:收集统计信息
INVALIDATE METADATA
REFRESH
impala 性能优化
维度建模
包含维度表、事实表、星型模型、雪花模型等。
维度模型是由一个规范化的事实表和反规范化(冗余)的一些维度表组成的(一种非规范化的关系模型;表与表之间的关系通过关键字和外键来定义)。
通过SQL或者相关的工具实现数据的查询和维护。
维表的特征:
- 包含了众多描述性的列:维表的范围很宽(具有多个属性)
- 通常情况下,跟事实表相比,行数相对较小:通常 < 10万条
- 内容相对固定:几乎就是一类查找表或编码表
文件存储格式
支持的文件存储格式包括:parquet、Text、Avro、RCFile 和 SequenceFile 等,后三种文件存储格式仅支持查询。
SQL Tuning
BROADCAST JOIN(小表+大表)将较小的表通过网络分发到所有需要执行该连接的impala后台进程中,参与连接的 impala 进程会根据数据建立哈希表并保存在内存中。
PARTITIONED JOIN(大表+大表)进行哈希连接时(也称shuffle join),每个impala进程读取两个表的本地数据,使用一个哈希函数进行分区并将每个分区分发到不同的impala进程。
分区:分为静态分区和动态分区。
-1. 静态分区:在 SQL 中指定所有分区列的值,如:
insert into t1 partition(x=10,y='a') select c1 from some_other_table;
-2. 动态分区:insert 语句中指定列名,在select语句中指定具体值。
insert into weather partition(year, month, day) select 'cloudy','2014.4.21'
compute stats
summary
profile
数据倾斜的优化(分布计算,最后合并;数据倾斜的JOIN KEY打散)
资源控制(配置资源池;高并发时连接到不同的IMPALAD节点)
合理利用 MEM_LIMIT 参数
正确使用invalidate metadata 与 refresh: 均可以用来刷新表,但本质是不同的。