hive 是基于 hadoop 的一个数据仓库工具。
hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能使SQL语句转变成 MapReduce 任务来执行。十分适合对数据仓库进行统计分析。
数据存储模型
hive 包含四类数据模型:表(Table)、外部表(External Table)、分区(Partition)、桶(Bucket)。
-
内部表和外部表
(创建)
内部表数据会移动到指定位置,一般默认存储的 hdfs 文件路径为 /usr/hive/warehouse/
外部表不会移动数据,Location 参数指定 HDFS 文件路径
(删除)
内部表删除,元数据和数据仓库目录下的实际数据将同时删除;
外部表删除,仅删除元数据,不删除保存在外部 HDFS 文件目录中的实际数据。
因此,区别明显:一般工作中使用外部表作为数据映射,而统计结果一般使用内部表,因为内部表仅仅用于储存结果或者关联,与 HDFS 数据无关。 - 分区
对应于数据库中的分区列的密集索引 - 分桶
对指定列进行哈希 (hash) 计算,会根据哈希值切分数据,目的是为了并行,每一个桶对应一个文件。
hive与关系型数据库区别
| 区别点 | hive | 关系数据库 |
|---|---|---|
| 存储文件系统 | HDFS | 本地文件系统 |
| 计算模型 | mapreduce | 自己设计 |
| 应用场景 | 为实时查询业务设计 | 为海量数据挖掘设计 |
| 扩展性 | 易扩展自己的存储和计算能力,继承的 hadoop | 较hive差 |
hive 启动方式
-1. 使用本地 metastore
hive-site.xml 配置使用本地 mysql 数据库存储 metastore
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
cd $HIVE_HOME/bin/hive
$HIVE_HOME/bin/hive --service cli # hive 命令默认是启动 client 服务的
-2. 使用远程 metastore
服务器1 如1中配置,使用本地 metastore
$HIVE_HOME/bin/hive --service metastore -p 9083 # 启动 metastore 服务
服务器2配置使用远程 metastore
<property>
<name>hive.metastore.uris</name>
<value>thrift://metastore_server_ip:9083</value>
</property>
$HIVE_HOME/bin/hive # 服务器2直接启动cli即可
-3. 启动 hiveserver2,使其他服务可通过thrift接入hive
hive-site.xml
<property>
<name>hive.server2.authentication</name>
<value>None</value>
</property>
core-site.xml 配置 hadoop 代理用户
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
$HIVE_HOME/bin/hive --service hiveserver2 # 启动 hiveserver2
$HIVE_HOME/bin/beeline -u jdbc:hive2://localhost:10000 # beeline 工具测试使用jdbc方式连接
hive 为什么要启用 metastore?
metadata 包含用hive创建的database、table等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore作用:
| 客户端连接metastore服务,Metastore再去连接MySQL数据库来存储元数据。有了Metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接Metastore服务即可。 |
metastore 的三种启动方式:
- 默认开启方式:没有配置metaStore的时候,每当开启bin/hive;或者开启hiveServer2的时候,都会在内部启动一个metastore;
- local Metastore:当metaStore和装载元数据的数据库(MySQL)存在同一机器上时配置是此模式;
- remote Metastore: 当metaStore和装载元数据的数据库(MySQL)不存在同一机器上时配置是此模式。
总结: 为什么集群要启用Metastore?因为启用后,直接bin/hive启动进程,只会有hive交互式客户端一个 服务,不会再有Metastore同时存在在该进程中,资源占有率下降,查询速度更快。
hive 排序函数
常用的三个排序函数 rank、row_number、dense_rank。
rank():相同的排序是一样的,而且下一个不同值是跳着排序的;
row_number():此方法不管排名是否有相同的,都按照顺序1,2,3…..n
dense_rank():此方法对于排名相同的名次一样,且后面名次不跳跃
hive 排序
order by: 会对查询结果集执行一个全局排序,也就是说所有数据都通过一个 reduce 进行处理的过程,对于大数据,这个过程将消耗很大的时间来执行。
sort by: 执行一个局部排序过程。保证每个reduce的输出数据都是有序的,这样可以提高后面进行全局排序的效率了。默认是 asc表示升序,desc表示降序。
在使用 sort by 之前,需要先设置 reduce 的数量 >1,才可做局部排序。若 reduce = 1,作用与 order by 一样,全局排序。
distribute by:保证具有相同年份的数据分发到同一个 reducer 中进行处理,然后使用 sort by 来按照我们的期望对数据进行排序。
cluster by:= distribute by + sort by,除了 distribute by 的功能外,还会对该字段进行排序。
hive 运行引擎
-
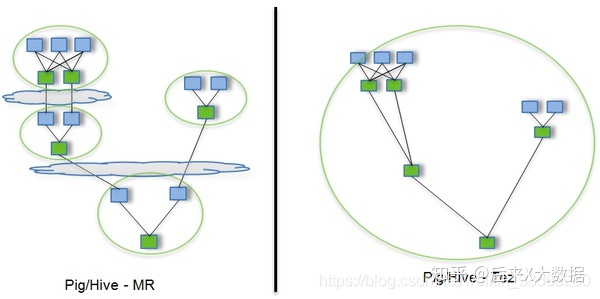
MR
MR将一个算法抽象成Map和Reduce两个阶段进行处理,如果一个HQL经过转化可能有多个job,那么在这中间文件就有多次落盘,速度较慢.
-
Tez
可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能.
-
spark
Spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。
Spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。同时Spark也提供了更丰富的计算API,例如filter,flatMap,count,distinct等。
过程间耦合度低,单个过程的失败后可以重新计算,而不会导致整体失败;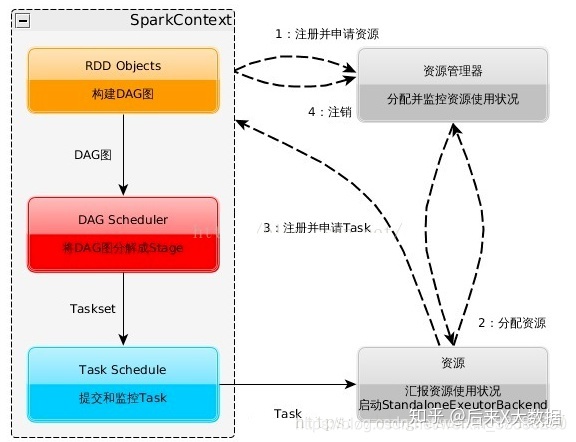
小结
-1. centos7 hive 安装
-2. 大数据时代的技术 hive
-3. hive的几种启动方式