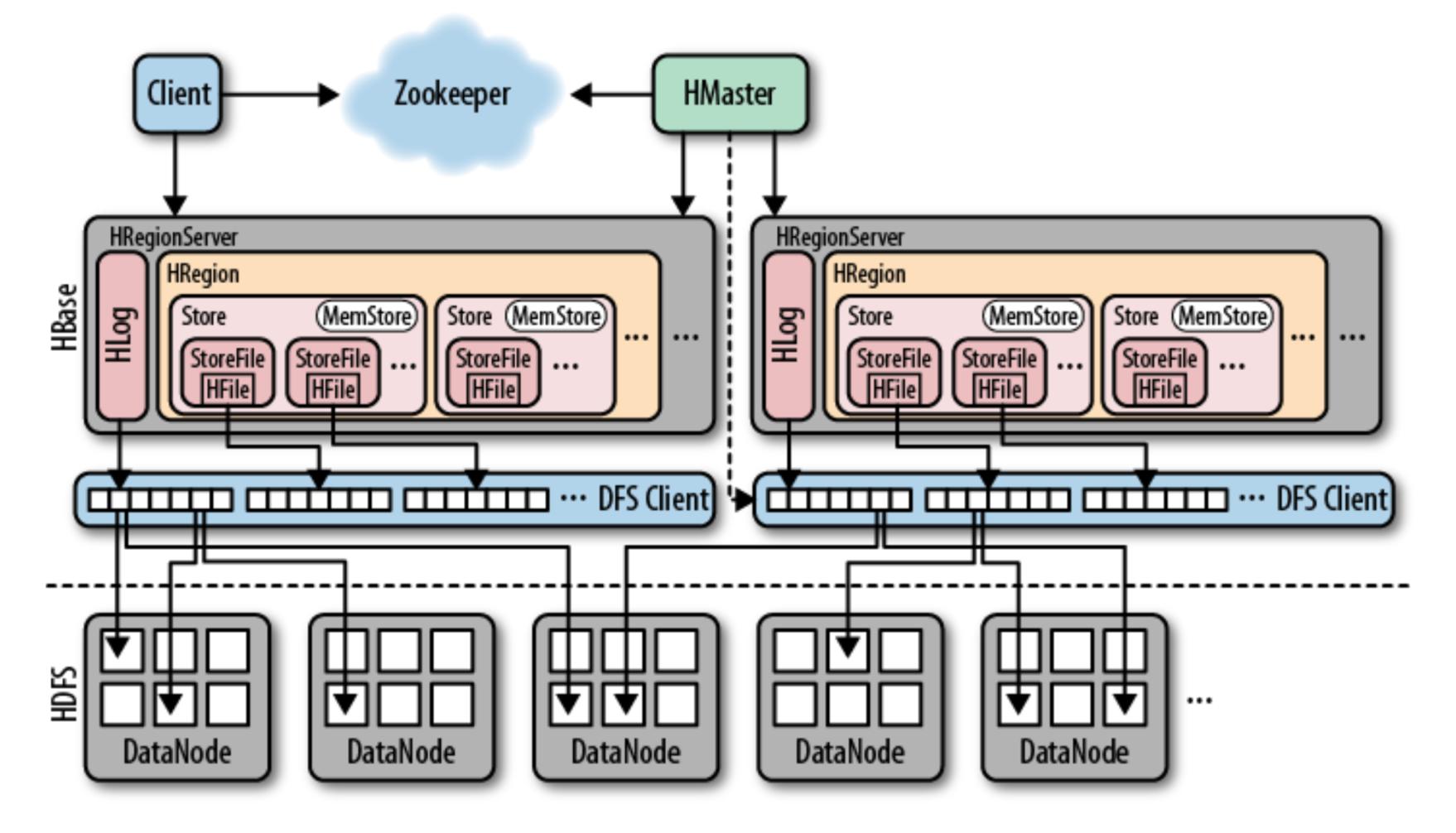
hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。
为什么 hbase 可以存储海量的数据?
因为 hbase 是在 HDFS 的基础上构建的,HDFS 是分布式文件系统。
关于 hbase 的详细介绍,可参见知乎回答。
另外,hbase 是一个主从架构的集群,部署时可以一主多从,也可以多主多从形成高可用机制。
hbase 的写流程
- client 通过 zk 的调度,向 regionServer 发出写数据请求,在 region 中写数据。
- 数据被写入 region 的 MemStore,直到 MemStore 达到预设阈值。
- MemStore 中数据被 Flush 成一个 storeFile。
- 随着 storeFile 文件的不断增多,当其数据增长到一定阈值后,触发 compact 合并操作,将多个 storeFile 合并成一个 storeFile,同时进行版本合并和数据删除。
- storeFile 通过不断的 compact合并操作,逐步形成越来越大的 storeFile。
- 单个 storeFile 大小超过一定阈值后,触发 split 操作,将当前 region split 成2个新的 region。父 region 会下线,新 split 出的2个子 region 会被 HMaster 分配到相应的 RegionServer 上,使得原先1个 region 的压力得以分流到 2个 region上。
client 提交一个 put 请求到 regionServer,数据首先会写到 WAL 中
当数据写到 WAL 之后,数据会写到 MemStore 中,等待刷新到磁盘中
数据写到 MemStore 完成之后,RS 会给 client 发送确认信息
compaction
MemStore 每次 Flush 会创建新的 HFile,而过多的 HFile 会引起读的性能问题,如何解决?
HBase 采用 compaction 机制来解决这个问题。
HBase 中的 compaction 分为两种:Minor compaction 和 Major compaction。
- Minor compaction 是指选取一些小的、相邻的 storeFile 将他们合并为一个更大的 storeFile,在这个过程中不会处理已经 deleted 或 expired 的cell。一次 Minor compaction 的结果是更少并且更大的 storeFile。
- Major compaction 是指将所有的 storeFile 合并成一个 storeFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间。
hbase 的读流程
- client 访问 zk,查找 -ROOT-表,获取 .META. 表信息。
- 从 .META. 表查找,获取存放目标数据的 region 信息,从而找到对应的 regionServer。
- 通过 regionServer 获取需要查找的数据。
- regionServer 的内存分为 memstore 和 blockcache 两部分,memstore 主要用于写数据,blockcache 主要用于读数据。读请求先到 memstore 中查找数据,查不到就到 blockcache 中查,再查不到就会到 storeFile 上读,并将读的结果放入 blockcache。
寻址过程: client -> zk -> -ROOT-表 -> META 表 -> regionServer -> region -> client
HMaster
HMaster 在 Hbase 中承担什么样的角色?
HMaster 会处理 HRegion 的分配或转移。如果我们 HRegion 的数据量太大的话,HMaser 会对拆分后的 region 重新分配 RegionServer(如果发现失效的 HRegion,也会将失效的 HRegion 分配到正常的 HRegionServer 中)。
HMaser 会处理元数据的变更和监控 RegionServer 的状态。
HFile
HBase 实际存储的数据格式
Hlog
我们在写数据的时候是先写到内存,为了防止机器宕机,内存的数据没刷到磁盘中就挂了。因此,我们在写Mem Store 的时候还会写一份 HLog。
HLog 是顺序写到磁盘的,所以速度还是挺快的。