flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,flume 提供对数据的简单处理,并写到各种数据接收方的能力。
flume 的数据流由事件(Event)贯穿始终。事件是flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息。
- flume 的可靠性
提供了三种级别的可靠性保障,从强到弱依次分为:
end-to-end:收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送;
store on failure:当数据接收方crash时,将数据写到本地,待恢复后,继续发送;
besteffort:数据发送到接收方,不会进行确认。 - flume 可恢复性
还是得靠 channel。推荐使用 filechannel,事件持久化在本地文件系统里(性能较差)。
flume 的一些核心概念
client:生产数据,运行在一个独立的线程。
Event:一个数据单元,消息头和消息体组成(events 可以是日志记录、avro 对象等)。
flow:event 从源头到达目的点的迁移的抽象。
agent:一个独立的 flume 进程,包含组件 source/channel/sink。(agent 使用 JVM 运行flume,每台机器运行一个agent,但是可以在一个agent中包含多个 sources 和 sinks)。
source:数据接受组件。
channel:中转 event 的一个临时存储,保存由source组件传递过来的 event。
sink:从 channel 中读取并移除 event,将 event 传递到 flowPipeline 中的下一个agent。
flume –kafkaChannel 的使用
在使用flume对接Kafka时,我们往往使用TailFileSource–>MemoryChannel–>KafkaSink的这种方式,然后将数据输送到Kafka集群中。
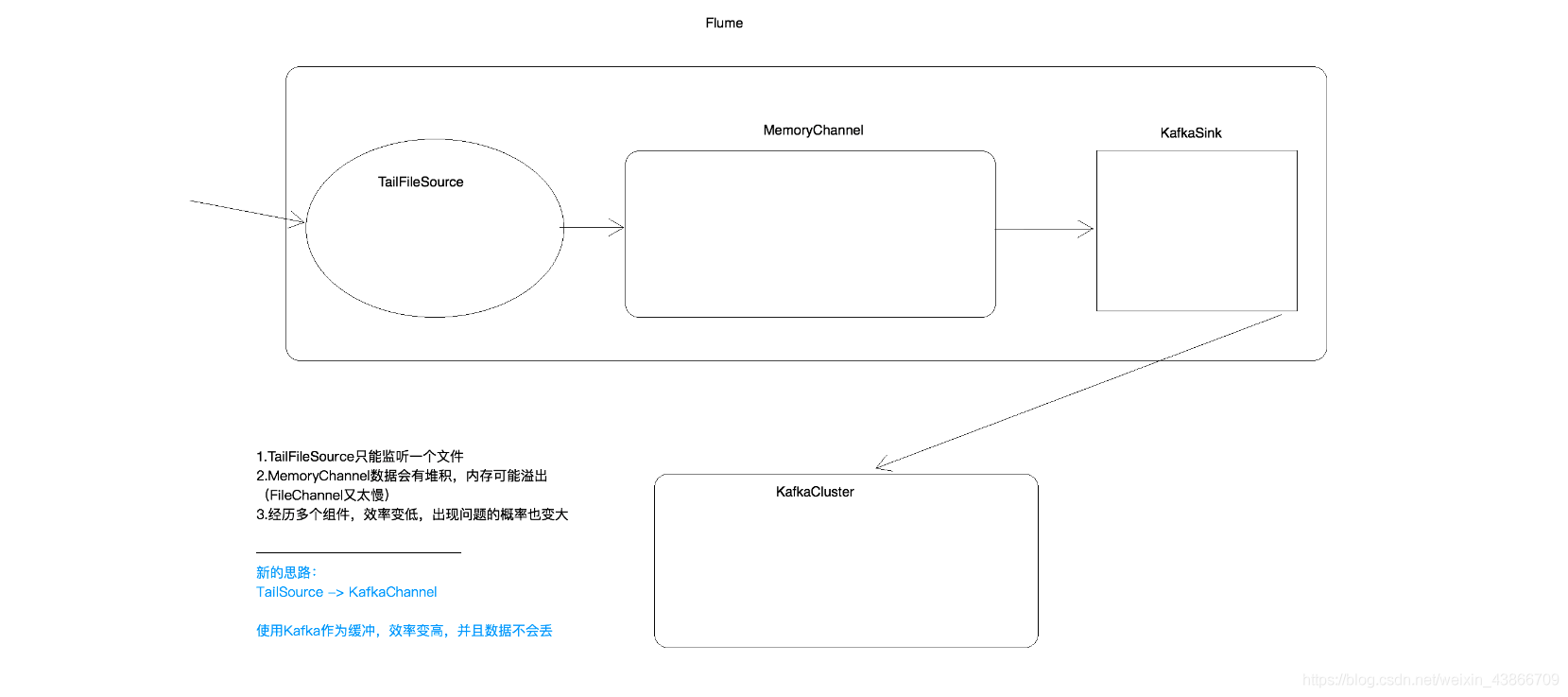
该方式存在弊端:
-1. TailFileSource 只能监听一个文件
-2. MemoryChannel 数据会有堆积,内存可能溢出(FileChannel比较慢)
-3. 该方式经历多个组件,效率变低,出现问题的概率也变大
新思路:使用 TailFileSource -> kafkaChannel -> kafka 集群,将kafkachannel作为缓冲,效率变高,而且数据不会丢失。此时,kafkaChannel 相当于 kafka的生产者,充分利用了kafka集群的优点,当数据量很大的时,也能 hold 住。
若要将数据写入至 HDFS 或者 ES中,要再创建一个flume集群,这个flume中只要有 kafkaChannel 和 HDFSSink 就可以了,此时的kafkaChannel 相当于kafka的消费者。但是需要注意,为了避免多个flume消费同样的数据,要将多个flume实例放在同一个组内。