数据仓库(Data Warehouse,简写为 DW/DWH)本身即不生产数据也不消费数据,只是作为一个中间平台集成化地存储数据。目的是构建面向分析的集成化数据环境。
数据仓库概念
数据仓库的特点
1) 数据仓库的数据是面向主题的
2) 数据仓库的数据是集成的
3) 数据仓库的数据是不可更新的
4) 数据仓库的数据是随时间不断变化的
数据仓库数据随着时间不断变化表现在3个方面:数据仓库随时间变化不断增加新的数据内容;数据仓库随时间变化不断删去旧的数据内容;数据仓库中包含有大量的综合数据,这些综合数据中很多跟时间有关,如数据经常按照时间进行综合或隔一段时间片进行抽样等等。这些数据要随着时间的变化不断地进行重新综合。因此,数据仓库的数据特征都包含时间项,以标明数据的历史时期。
数据仓库发展历程
简单报表阶段 –> 数据集市阶段 –> 数据仓库阶段(与数据集市的建设重要区别在于数据模型的支持)
数据库与数据仓库的区别
| OLTP(on-line transaction processing) | OLAP(on-line analytical processing) |
|---|---|
| 操作型处理 | 分析型处理 |
| 细节的 | 综合的或提炼的 |
| 实体 – 关系(E-R)模型 | 星型模型或雪花模型 |
| 存储瞬时数据 | 存储历史数据,不包含最近的数据 |
| 可更新的 | 只读、只追加 |
| 一次操作一个单元 | 一次操作一个集合 |
| 性能要求高,响应时间短 | 性能要求宽松 |
| 面向事务 | 面向分析 |
| 一次操作数据量小 | 一次操作数据量大 |
| 支持日常操作 | 支持决策需求 |
| 数据量小 | 数据量大 |
| 客户订单、库存水平和银行账户查询等 | 客户收益分析、市场细分等 |
数据库与数据仓库的对比
| 属性 | 数据库 | 数据仓库 |
|---|---|---|
| 面向内容 | 事务 | 主题、分析 |
| 数据存储 | 当前最新数据 | 历史数据 |
| 模型建设 | 三范式 | 星型模型 |
三范式
第一范式(1NF):每一列都是不可分割的原子数据项
第二范式(2NF):在1NF基础上,非码属性必须完全依赖于候选码
第三范式(3NF):在2NF基础上,任何的非主属性不依赖于其他非主属性
主属性:码中所有属性
非主属性:除码之外的所有属性
数据仓库的架构分层
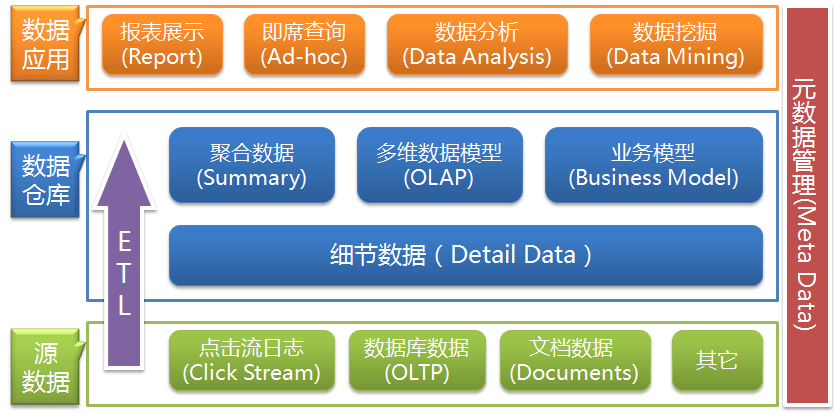
通常情况下,数据仓库分为三层:源数据、数据仓库、数据应用。
标准上可以分为四层: ODS、DWD、DWS、ADS。
-
ODS(原始数据层)
用于保存原始数据,原始数据可有多个来源;
-
DWD(明细层)
用于还原业务过程,保存最细粒度的数据,对原始数据按照不同的模式进行ETL处理,完成数据清洗和部分业务逻辑处理等过程;
-
DWS(聚合层)
存放的为非明细的数据,通常是经过各种计算以后得到的轻度聚合和重度聚合数据,主要采用维度建模方法进行构建;
-
ADS(应用层)
为了满足业务需要而产生的结果化数据,具有很强的定制性,主要提供给相关数据应用外部系统,以及对特定数据有需求的人员使用。是数据仓库和外部的接口,主要对接其他系统,如业务报表、报表系统等。
为什么要对数据仓库分层?
1) 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;
2) 如果不分层,若源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大;
3) 通过数据分层管理可以简化数据清洗的过程,因为将原来异步的工作分到了多个步骤去完成,相当于将一个复杂的工作拆分成了多个简单的工作,将一个大的黑盒编程了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
元数据
元数据的定义
数据仓库的元数据是关于数据仓库中数据的数据。它的作用类似于数据库管理系统的数据字典,保存了逻辑数据结构、文件、地址和索引等信息。广义上讲,在数据仓库中,元数据描述了数据仓库内数据的结构和建立方法的数据。
元数据是数据仓库管理系统的重要组成部分,元数据管理器是企业级数据仓库中的关键组件,贯穿数据仓库的整个过程,直接影响着数据仓库的构建、使用和维护。
-1 构建数据仓库的主要步骤之一是ETL;
-2 用户在使用数据仓库时,通过元数据访问数据,明确数据项的含义及其定制报表;
-3 数据仓库的规模及其复杂性离不开正确的元数据管理,包括增加或移除外部数据源,改变数据清洗方法,控制出错的查询以及安排备份等。
元数据分类
元数据可分为技术元数据和业务元数据。
元数据存储方式
常见有两种存储方式:一种以数据集为基础,一种以数据库为基础。
元数据的作用
1) 描述哪些数据在数据仓库中,帮助决策分析者对数据仓库的内容定位;
2) 定义数据进入数据仓库的方式,作为数据汇总、映射和清洗的指南;
3) 记录业务时间发生而随之进行的数据抽取工作时间安排;
4) 记录并检测系统数据一致性的要求和执行情况;
5) 评估数据质量。
星型模型和雪花模型
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花模型。
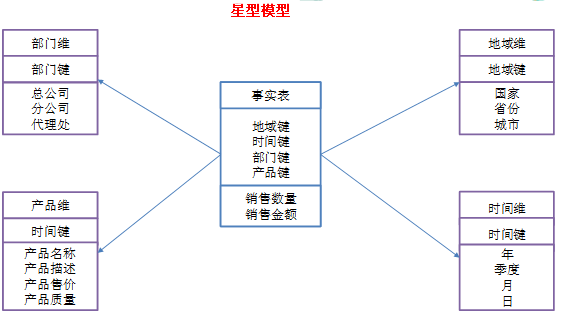
星型模型
当所有维表都直接连接到”事实表”上时,整个图解就像星星一样,故称为星型模型。
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余。
雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,且图解就像多个雪花连接在一起,故称雪花模型。
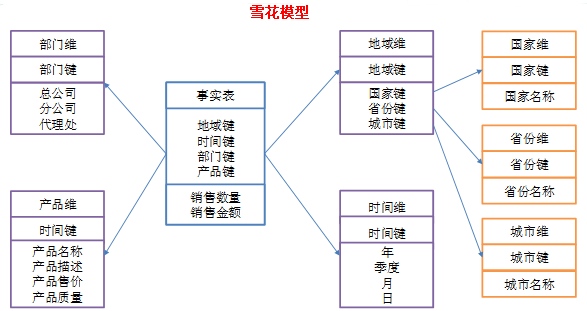
星型模型因为数据冗余所以许多查询不需要做外部的连接,因此一般情况下效率比雪花模型要高。
星型模型与雪花模型对比
1) 数据优化
雪花:使用的是规范化数据,即数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型中。
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。
星型:是反规范化数据。
2) 业务模型
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。在星型模型中,所有必要的维度表在事实表中都有只拥有外键。
3) 性能
雪花模型在维度表、事实表之间的链接很多,因此性能方面会比较低。
4) ETL
雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。
星型模型加载维度表,不需要在维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
总结
雪花模型使得维度分析更加容易,星型模型用来对指标分析更加适合。
针对维度和指标的区别,详见链接。
参考文献
-1. 数据仓库理论
-2. 数据仓库的基础架构
-3. 爱奇艺数据仓库平台和服务建设实践
-4. 8000字详解数据仓库建设中的数据建模方法